
Big Data Quintessence: Measuring Equality

Editor | On 26, Jun 2018
Darrell Mann
The state of the art when it comes to measuring things like gender equality is that the powers that be conduct ethnographic research and identify simple correlating factors. Hence we will typically find things like the number of female judges and politicians within a country being used as measures of equality. While such measures certainly satisfy the criterion of being easy to measure, their relevance in terms of either the population at large or their susceptibility to corruption makes them effectively meaningless.
The other end of the measurement spectrum can be seen in the world of Big Data Analytics. Big Data sacrifices the depth of ethnographic research and replaces it with computer algorithms that sift through potentially enormous amounts of narrative data in order to extract correlations based on, usually, word counts or, at best, some kind of crude sentiment analysis. But the knowledge that words like ‘sexist’, ‘feminist’ or ‘positive discrimination’ are in regular usage in a country, or that women are on average more frustrated than men actually tells us very little about the prevailing inequality.
What we see when we think of this kind of spectrum is actually two sides of a contradiction: data is either BIG or THICK: lots of superficial thin data, or very small amounts of deeply thought through data that might actually contain some modicum of insight. Most organisations assume they have to choose a Big Data solution that sits somewhere along that spectrum. Here in the TRIZ/SI world, we know that the best thing to do is solve the contradiction. The ideal solution would be both BIG and THICK. It would, in other words, be both wide-reaching and capable of picking out real insight. It’s what we’re coming to think of as the ‘quintessential’ or quintessence solution – Figure 1.
So, when it comes to measuring equality, the trick is to be able to search through large quantities of narrative and other content and to be able to look beyond the mere words that are being used to see a deeper picture. Look at different parts of the world today, or look at how equality issues and awareness have evolved over time and we can quickly begin to see the subject has very little to do with counting the number of times words like ‘feminist’ appear. In the UK right now, for example, 20% of Generation Y women believe that being called a ‘feminist’ is an insult. Go back ten or so years before Generation Y came along and comedians were making jokes about the subject. Go back ten years further still and women were burning their bras. As context changes, the language of equality – or its opposite – changes. The question, if we’re ever to meaningfully measure things like equality is ‘does it change in a repeatable manner?’
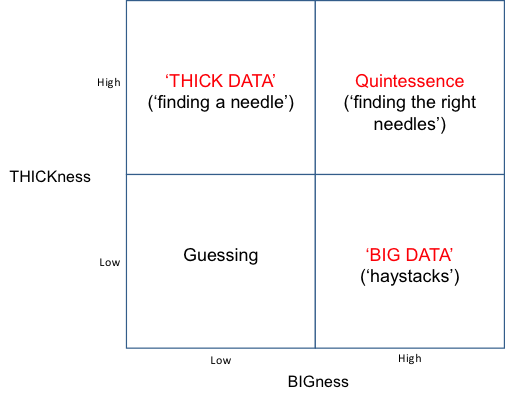 Figure 1: The BIG versus THICK Data Contradiction
Figure 1: The BIG versus THICK Data Contradiction
Our investigation to answer the question harnessed the 15-year development pedigree underpinning our suite of proprietary PanSensic narrative analysis tools. Initiated originally following large pieces of consumer anthropology research with some of the world’s foremost multi-national corporations, the heart of PanSensic is to get beyond what people say to reveal what they actually mean. We’ve all been in a restaurant and been accosted by waiting staff apparently keen to know how much we’re enjoying our meal. And we all know that what we’ve told that person has very little to do with our reality. Our job is to get rid of the person as quickly as possible without causing offence. PanSensic is all about capturing the so-called ‘unspoken’ sentiment. Over the years we have developed a number of strategies for achieving this goal by analysing unstructured narrative data in novel ways. We now know, for example, that the rationalising part of our brain (the prefrontal cortex) is very good at rationalising a situation in order to construct the gentlest possible lie, but it isn’t good enough to reframe the metaphors we use. Analyse the metaphors and we have a much greater insight into what people actually think. Are they sexist? Racist? The metaphors they use will tell us.
Hence the heart of a possible equality measurement tool answer is about evolving the core PanSensic ‘read between the lines’ capability and deploy it to help measure inequalities. The current suite of PanSensic tools all work in the same basic manner: We work out an ontology defining what to measure; we define a series of keywords that define whether and where a piece of data fits within that ontology; we use a semantic-engine to establish whether the found keyword is being used within the context of the desired ontology; and then we interpret what the analysis tells us. These capabilities already exist within the PanSensic tools. They’ve been designed primarily to analyse a given situation in a single time-slice context.  Being able to detect inequality – whether it be gender, race, religion or any other form of discrimination – requires a somewhat more sophisticated set of detection algorithms. The first phase of solving the overall puzzle, therefore, needs to establish how the language of equality – or any other subject for that matter – changes as a function of time. We have found ourselves focusing on 3 areas:
The first, and most important builds from the recognition that the journey from ‘unconscious incompetence’ about an inequality issue (i.e. the problem exists but isn’t recognised as such), through to ‘unconscious competence’ (when the solution is so engrained across a population that it no longer forms a topic of conversation) involves a number of inevitable stages, and that depending on where along this journey a population is, the inequality agenda will shift. Thus, to take the example of gender equality, there will be a period of anger (e.g. Suffragette movement), there will be a period of ‘positive discrimination’, there will be a period when society can joke about the subject, and there will be a period when the ‘victims’ desire to dis-associate themselves from the protest, and then, finally, a time when people no longer see what the protests were all about and the whole topic becomes a historical curiosity. This generic evolution path from unconscious competence through conscious competence, to conscious competence, and finally to unconscious competence thus forms the core of a timescale-dependent equality model:
 Figure 2: The Journey From Unconscious Incompetence To Unconscious Competence
Figure 2: The Journey From Unconscious Incompetence To Unconscious Competence
The second stage then took a more detailed look at each of the four phases of the competence journey. Two of the four stages in particular quickly emerged as the subject of much prior research by others. The Conscious Incompetence stage, for example, is all about realizing we’re wrong about something, and that the human brain effectively passes through a Grief Cycle (Reference 1) every time we realise we’re wrong about an issue, no matter how trivial it might be. As shown in Figure 2, the basic stages of the Grief Cycle are the same irrespective of whether we’re grieving for a lost relative or whether a friend just asked us a Trivial Pursuit question and we got that wrong. Only the duration of the cycle differs: getting over the lost relation might take years; getting over failing to remember the capital city of Uruguay might take a few minutes. Either way, getting something wrong – like assuming men are somehow superior to women, a trait that seems to have affected the male population from around 200,000BC through to around the 1928 (or 1971 if you happen to live in Switzerland), involves a period of Denial, then Anger, then Depression, then Bargaining, and finally Acceptance. The language used and emotions expressed by both sides of the equality issue vary in each of these phases, and thus any analysis tool needs to be able to recognize each of them separately.
The same sort of thing happens during the next stage of the Competence journey. Conscious Competence is all about learning cycles, of which, again, in classic ‘someone, somewhere already solved your problem’ fashion, there are multiple different models to play with. The one we ended up using is also shown in Figure 2 – Connect-Activate-Demonstrate-Consolidate.
The third piece of the jigsaw, finally (so far at least), is to recognize the importance of tracking the language being used not only by those on either side of the particular equality issue (i.e. men and women when we’re thinking about gender equality), but also those that effectively take up an active role at the boundaries between the two. We’ve tried to represent this third faction by the white diamond-shaped region in the Figure 2 plot. It is diamond shaped because during the conscious incompetence and conscious competence stages of the overall evolution journey, there is an increasing followed by decreasing need for activists, champions and protestors. The third aspect to an equality measure, therefore is working out what proportion of a population falls into this diamond-shaped category. And the best way to do that is to, again, look across as wide a span of the population and, these days, social media in order to establish how many people are using which sorts of language.
Bolt all that together and, so we’re beginning to be able to demonstrate to ourselves and our pioneering equality-measuring clients, the mess of apparently conflicting messages and narrative begins to become clear:

Work out when comedians are making jokes about an equality issue and you know where in the journey you are (conscious competence, activate). Work out when expressions like ‘positive discrimination’ are being used and you know where you are in the journey (conscious incompetence, bargaining). Work out when those on the ‘oppressed’ side of the inequality story are seeking to distance themselves from it, and you know where you are in the journey (conscious competence, consolidate). It’s not a perfect science yet, but it’s getting there, and, we already know it’s a far more effective way of measuring reality than counting the number of judges of a particular gender, race or creed. And, thanks to PanSensic, it’s also, now everything is set up, an awful lot easier to do.
Reference
- Kubler-Ross, E., Kessler, D., ‘On Grief And Grieving: Finding The Meaning Of Grief Through The Five Stages Of Loss’, Simon & Schuster Re-issue Edition, 2014.